Der InMemory Adapter wurde zur schnellen Datenaufbereitung entwickelt um die immer größer werdenden Hauptspeichergrößen der vorhandenen Rechner/Server besser ausnutzen zu können. Gerade bei der Verarbeitung von Komplexen/Großen FlowHeater Definition kann so eine deutliche Leistungssteigerung erreicht werden.
Dabei unterstützt der InMemory Adapter „beliebig“ viele „temporäre“ Tabellen die im Prinzip wie SQL Datenbank Tabellen verwendet werden können. Im Unterschied zu SQL Datenbank Tabellen werden InMemory Tabellen, wie der Name schon suggeriert, nur im Hauptspeicher vorgehalten. Außerdem kann auf diese InMemory Tabellen über den Hauptspeicher rasend schnell zugegriffen werden, da hier keine Latenzzeiten für Verbindungsaufbau, sowie Netzwerk, etc. vorhanden sind. Die Datenmenge die so mit dem InMemory Adapter verarbeitet werden kann ist lediglich vom frei verfügbaren Hauptspeicher des Computers abhängig.
Mögliche Datenmengen 32Bit (x86) vs. 64Bit (x64)
Die FlowHeater 32Bit Variante kann egal wieviel freier Hauptspeicher verfügbar ist lediglich auf max. 2 GB Hauptspeicher zugreifen. Die FlowHeater 64Bit Variante kann im Prinzip auf den komplett frei verfügbaren Hauptspeicher zugreifen und diesen für die Verarbeitung verwenden.
Rechenbeispiel
Nehmen wir an, ein einzelner Datensatz hat eine Größe von 2 KByte (=2.048 Bytes), was schon recht viel ist. Bei einer Million (1.000.000) Datensätzen werden so 2GB für die Nutzdaten benötigt.
2KB x 1.000.000 = 2GB
Der InMemory Adapter benötigt ca. nochmal 20% für interne Verwaltungsinformationen. Also wird bei der Verarbeitung dieser 1.000.000 Datensätze insgesamt ca. 2,4 GB freier Hauptspeicher benötigt. Ist mehr Arbeitsspeicher frei können noch größere Datenmengen verarbeitet werden.
PS: Achten Sie darauf, dass immer genügend freier Hauptspeicher vorhanden ist, nicht dass auf dem Rechner die evtl. konfigurierte Auslagerungsdatei zur Verarbeitung herangezogen wird! Das würde die Verarbeitungsgeschwindigkeit ausbremsen bzw. deutlich reduzieren.
Anwendungsgebiete
Mit dem InMemory Adapter können z.B. problemlos unterschiedliche Datenquellen zusammengeführt oder aber vorhandene Daten um weitere Daten angereichert werden. Weiterhin können große Ersetzungslisten für „CSV/Daten Lookups“ temporär eingelesen werden. Auf diese Tabellen kann dann sehr effizient mittels des String Replace Heater (CSV Lookup) oder aber SQL Heater bzw. Lookup Heater zugegriffen werden. Diese Heater/Funktionen bieten einen direkten Zugriff auf InMemory Adapter Tabellen an wodurch die Verarbeitungsgeschwindigkeit nochmals deutlich gesteigert werden kann.
Konfiguration
Reiter „Allgemein“
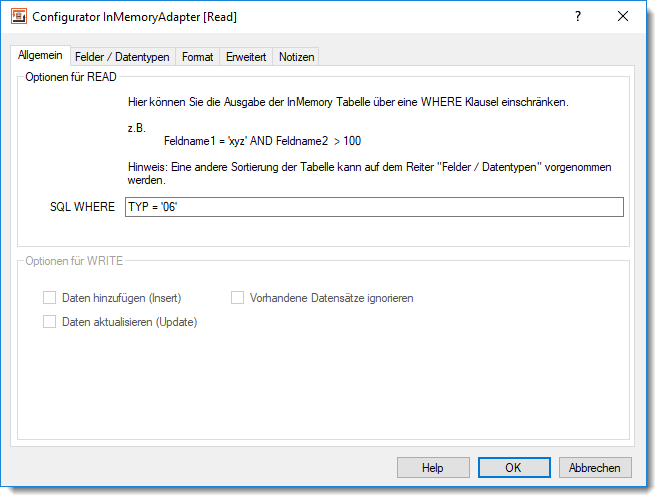 InMemory Adapter - Reiter AllgemeinJe nachdem auf welcher Seite der InMemory Adapter verwendet wird können Sie hier folgende Einstellungen vornehmen.
InMemory Adapter - Reiter AllgemeinJe nachdem auf welcher Seite der InMemory Adapter verwendet wird können Sie hier folgende Einstellungen vornehmen.
READ Seite: Ist es erforderlich nicht den kompletten aktuellen Inhalt der „temporären“ Tabelle auszugeben können Sie hier eine SQL WHERE Klausel angeben, mit der die Datenmenge eingeschränkt werden soll. Die WHERE Klausel hat die gleiche Syntax wie sie auch von normalen SQL Datenbank Tabellen verwendet wird.
WRITE Seite: Hier können Sie angeben welche Aktionen der InMemory Adapter beim Schreiben in die Tabelle vornehmen soll. Es stehen folgende Optionen zur Verfügung.
Daten anfügen (Insert): Ist diese Option aktiv werden die Daten an die „temporäre“ InMemory Tabelle angefügt.
Daten aktualisieren (Update): Ist diese Option aktiviert versucht der InMemory Adapter anhand der definierten Schlüsselfelder (Primary Key) vorhandene Datensätze in der Tabelle zu finden und zu aktualisieren.
Vorhandene Datensätze ignorieren: Wird diese Option aktiviert werden evtl. vorhanden Datensätze nicht erneut an die Tabelle angefügt. Hierzu ist es ebenfalls erforderlich, dass Schlüsselfelder (Primary Keys) definiert sind.
Hinweis: Die Optionen „Daten anfügen (Insert)“ und „Daten aktualisieren (Update)“ sowie „Daten anfügen (Insert)“ und „Vorhandene Datensätze ignorieren“ können zusammen kombiniert verwendet werden. Der InMemory Adapter entscheidet dann automatisch anhand der auf dem Reiter „Felder / Datentypen“ definierten Schlüsselfelder (Primary Keys) welche Aktion notwendig ist.
Reiter „Felder / Datentypen“
 InMemory Adapter - Felder / DatentypenAuf diesem Reiter können temporäre InMemory Tabellen angelegt, umbenannt, gelöscht und ausgewählt werden. Standardmäßig ist eine Tabelle „Default“ vorhanden. Es können aber beliebig viele weitere InMemory Tabellen angelegt werden. Den Tabellen können wiederum beliebige Felder hinzugefügt werden. Ändern Sie ein Feld (Name, Datentyp, etc.) wird dieses Feld automatisch in allen InMemory Adaptern, die die gleiche InMemory Tabelle verwenden geändert.
InMemory Adapter - Felder / DatentypenAuf diesem Reiter können temporäre InMemory Tabellen angelegt, umbenannt, gelöscht und ausgewählt werden. Standardmäßig ist eine Tabelle „Default“ vorhanden. Es können aber beliebig viele weitere InMemory Tabellen angelegt werden. Den Tabellen können wiederum beliebige Felder hinzugefügt werden. Ändern Sie ein Feld (Name, Datentyp, etc.) wird dieses Feld automatisch in allen InMemory Adaptern, die die gleiche InMemory Tabelle verwenden geändert.
Zusätzlich können je nachdem auf welcher Seite der Adapter verwendet wird folgende Einstellungen durchgeführt werden.
Auf der READ Seite: Hier können Sie eine optionale Sortierung für die Ausgabe der Tabelle angeben. Es ist möglich die Sortierung über mehrere Felder hinweg durchzuführen. Um die Ausgabe zu sortieren klicken Sie das gewünschte Feld an und aktivieren die Option „Ausgabe sortieren“. Daneben können Sie noch angeben ob die Sortierung „Aufsteigend“ oder „Absteigend“ erfolgen soll. Soll über mehrere Felder sortiert werden kann die Sortierung über die Feldreihenfolge weiter beeinflusst werden, dazu einfach die Feldreihenfolge hier verändern.
Auf der WRITE Seite: Falls auf der Tabelle UPDATES durchgeführt werden sollen können Sie pro InMemory Adapter einen oder mehrere Schlüsselfelder definieren anhand der InMemory Adapter versucht, bereits vorhandene Datensätze zu identifizieren. Hinweis: Es können in unterschiedlichen Verarbeitungsschritten mehrere InMemory Adpater verwendet werden, die die gleiche „temporäre“ Tabelle verwenden. Die Schlüsselfelder werden aber pro Adapter angelegt! Soll heißen, dass in unterschiedlichen Verarbeitungsschritten Daten anhand unterschiedlicher Schlüsselfelder aktualisiert werden können.
Ist zusätzlich die Option „Eindeutigen Schlüssel anlegen (Primary Key)“ aktiviert, wird der Schlüssel als Eindeutig (Unique) angelegt. Mit dieser Option aktivieren Sie die schnelle Verarbeitung bei großen Datenmengen sobald anhand dieser Schlüsselfelder Daten gesucht oder aber aktualisiert werden sollen. Achtung: Die Daten müssen dann auch wirklich eindeutig anhand des definierten Schlüssels in der Tabelle vorhanden sein!
Reiter „Format“
Der Reiter Format wird im allgemeinen Adapter Kapitel beschrieben.
Reiter „Erweitert“
Erweiterte Einstellungen
 InMemory Adpater - Reiter ErweitertLeerzeichen automatisch am Anfang und Ende des Inhaltes entfernen: Wenn Sie diese Option aktivieren werden evtl. vorhandene Leerraumzeichen am Anfang und Ende des Feldinhaltes automatisch entfernt. Diese Einstellung greift ausschließlich bei Feldern des FlowHeater Datentyps „STRING“.
InMemory Adpater - Reiter ErweitertLeerzeichen automatisch am Anfang und Ende des Inhaltes entfernen: Wenn Sie diese Option aktivieren werden evtl. vorhandene Leerraumzeichen am Anfang und Ende des Feldinhaltes automatisch entfernt. Diese Einstellung greift ausschließlich bei Feldern des FlowHeater Datentyps „STRING“.
Automatisch vorhandene Zeilenumbrüche in Feldnamen ersetzen mit Wenn Sie diese Option aktivieren können Sie Zeilenumbrüche im Feldinhalt automatisch durch die nachfolgend angegebenen Zeichen ersetzen lassen.
Logging
Erweitertes Logging aktivieren: Hier können Sie angeben, dass der Adapter die durchgeführten Aktionen in ein vorgegebenes Logfile protokollieren soll. Wenn Sie die Option „Anfügen“ aktivieren werden die Ausgaben an das angegebene Logfile angefügt ansonsten wird das Logfile vor der Ausführung geleert bzw. gelöscht.
Verwende im Batch definiertes Logfile: Wenn Sie diese Option aktivieren, verwendet der Adapter zur Protokollierung das im Batch Modul angegebene Logfile.
Feld Trennzeichen: Hier können Sie ein Trennzeichen angeben, das verwendet wird, um die einzelnen Feldinhalte voneinander zu trennen.
Felder quotieren: Die Feldinhalte werden mit diesem Zeichen umschlossen.