CSV text file import into PostgreSQL database
This example describes how the TextFile Adapter can be used to import a CSV text file into an PostgreSQL database table. It also explains how to configure FlowHeater for importing with insert or update SQL operations.
Note: An export of data to a CSV or flat file follows the same principles, but where the Adapters on the READ and WRITE sides are swapped over.
Let’s get started. First create a new PostgreSQL database to contain the import. To achieve this, use pgAdmin III and create a new database called "FlowHeater". Then run the following SQL script to create the Import table:
(
"ID" serial NOT NULL,
"Title" character(5),
"Firstname" character varying(50),
"Lastname" character varying(50),
"Street" character varying(50),
"PostalCode" character(5),
"City" character varying(50),
"BirthDate" date,
CONSTRAINT "PK_ID" PRIMARY KEY ("ID")
)
WITH (OIDS=FALSE);
ALTER TABLE "Import" OWNER TO postgres;
This results in a new table with 8 columns and a Primary Key. The Primary Key (ID field) has the PostgreSQL datatype SERIAL because a auto increment column. The unique values assigned to the ID will be determined by the PostgreSQL databse itself and FlowHeater is not involved in this.
Choose import Adapter
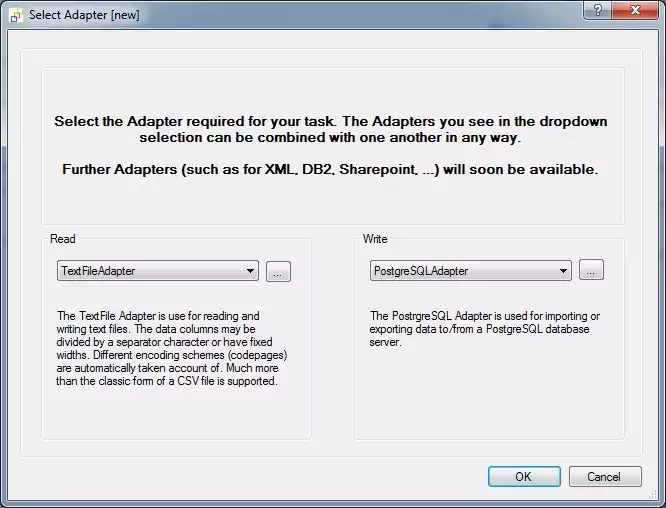 choose import AdapterNow open FlowHeater and click on the menu option "New" to create a new Definition. In the resulting popup window select for the READ side the TextFile Adapter and for the WRITE side the PostgreSQL Adapter.
choose import AdapterNow open FlowHeater and click on the menu option "New" to create a new Definition. In the resulting popup window select for the READ side the TextFile Adapter and for the WRITE side the PostgreSQL Adapter.
CSV text file import properties
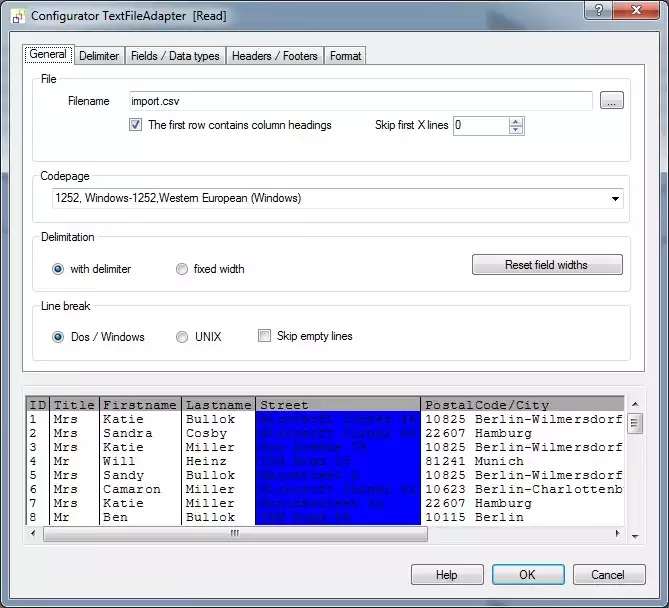 CSV text file import propertiesConfirm with OK to close the popup and now open the Configurator for the READ Adapter and select the file import.csv in the directory "Examples\EN\PostgreSQLAdapter". Check the checkbox "First row contains field names" and confirm the request of whether the field names should be loaded. All other settings on this page/tab should remain their defaults.
CSV text file import propertiesConfirm with OK to close the popup and now open the Configurator for the READ Adapter and select the file import.csv in the directory "Examples\EN\PostgreSQLAdapter". Check the checkbox "First row contains field names" and confirm the request of whether the field names should be loaded. All other settings on this page/tab should remain their defaults.
PostgreSQL databse connection properties
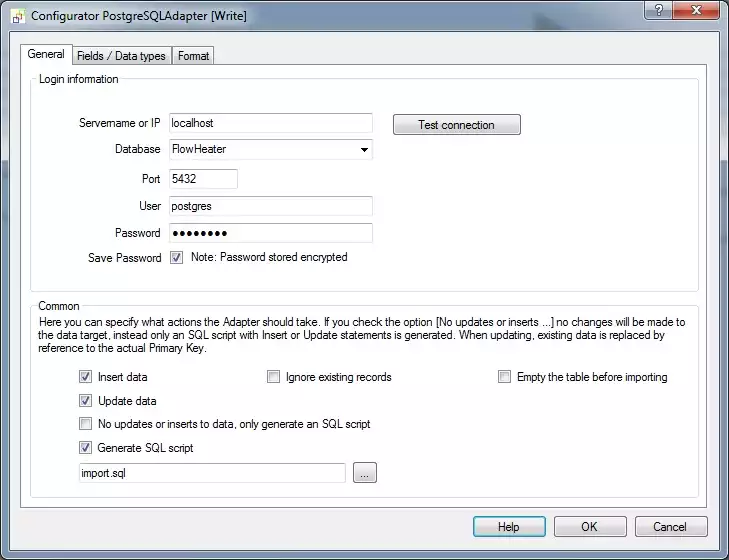 PostgreSQL databse connection propertiesTerminate the popup window with OK and open the Configurator for the WRITE Adapter.
PostgreSQL databse connection propertiesTerminate the popup window with OK and open the Configurator for the WRITE Adapter.
Enter the PostgreSQL Server connection parameters applicable to your database server e.g. "localhost" or the computer name and click the "Test Connection" button. Once a connection has been achieved, select from the databases listed in the dropdown, selecting the "FlowHeater" database we just created.
PostgreSQL, import fields and data type
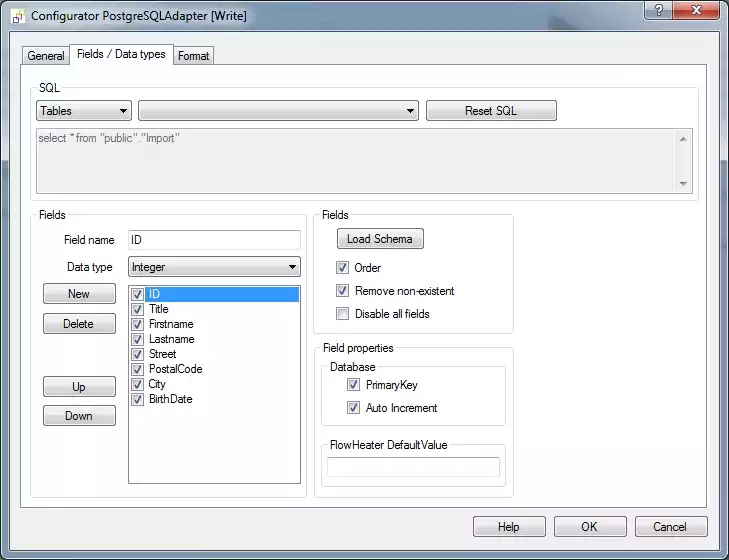 PostgreSQL, import fields and data typeNow switch to the Fields / Data types tab. Choose the "puplic"."Import" table from the dropdown and then click the "Load Schema" button to load the schema. This will import the field information of the table from the PostgreSQL server in order to save these as part of the FlowHeater Definition.
PostgreSQL, import fields and data typeNow switch to the Fields / Data types tab. Choose the "puplic"."Import" table from the dropdown and then click the "Load Schema" button to load the schema. This will import the field information of the table from the PostgreSQL server in order to save these as part of the FlowHeater Definition.
The details imported include the field names, data types, key information (Primary Key) and whether a field is assigned the “Auto Increment” attribute.
Important: The information imported at this stage can subsequently be modified to suit special cases. For example, you can amend Primary Key fields that are used to determine which fields the PostgreSQL Adapter uses to perform an update function. However, such manual modifications do not alter the underlying PostgreSQL table.
Autoconnect CSV-SQL fields
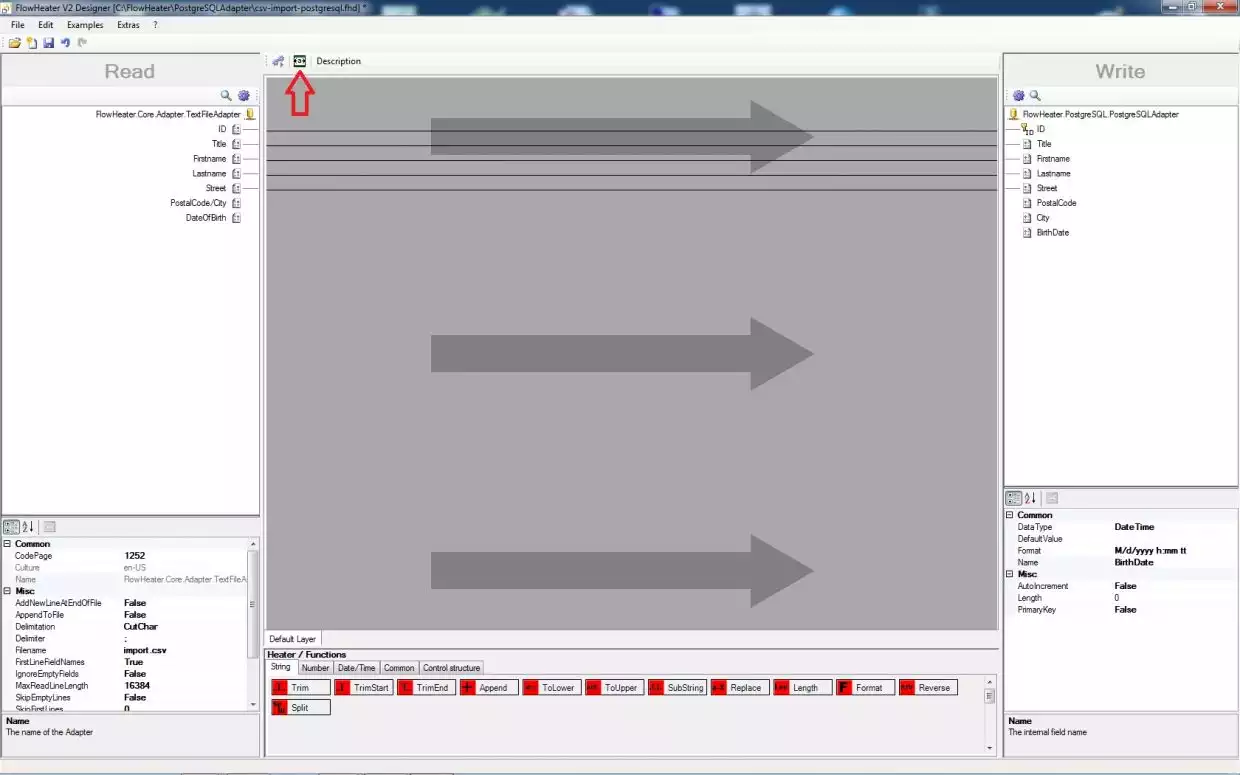 Autoconnect CSV-SQL fieldsClose the Configurator popup with OK and click on the Designer command "Automatically connect fields" (circled in red). Your screen should now appear similar to the screenshot on the right. Notice that we now have 2 unconnected fields on the READ side and 3 on the WRITE side. First construct a Pipe to connect the DateOfBirth field to the BirthDate field by dragging and dropping from one field to the other. Now move the mouse over this Pipe so that it is becomes bolder, indicating it is selected, and right mouse click to open the context menu for the Pipe. Choose the menu option Insert a Clone Heater. At your right mouse click position on the Pipe a Clone Heater will be inserted. Drag the newly inserted Heater further down the design area, stretching the Pipe with it. This makes some space where we can to insert two more Heaters, to split the combined PostalCode/City string field into two separate string fields as PostCode and City in our PostgreSQL database table.
Autoconnect CSV-SQL fieldsClose the Configurator popup with OK and click on the Designer command "Automatically connect fields" (circled in red). Your screen should now appear similar to the screenshot on the right. Notice that we now have 2 unconnected fields on the READ side and 3 on the WRITE side. First construct a Pipe to connect the DateOfBirth field to the BirthDate field by dragging and dropping from one field to the other. Now move the mouse over this Pipe so that it is becomes bolder, indicating it is selected, and right mouse click to open the context menu for the Pipe. Choose the menu option Insert a Clone Heater. At your right mouse click position on the Pipe a Clone Heater will be inserted. Drag the newly inserted Heater further down the design area, stretching the Pipe with it. This makes some space where we can to insert two more Heaters, to split the combined PostalCode/City string field into two separate string fields as PostCode and City in our PostgreSQL database table.
Insert Heater/Functions
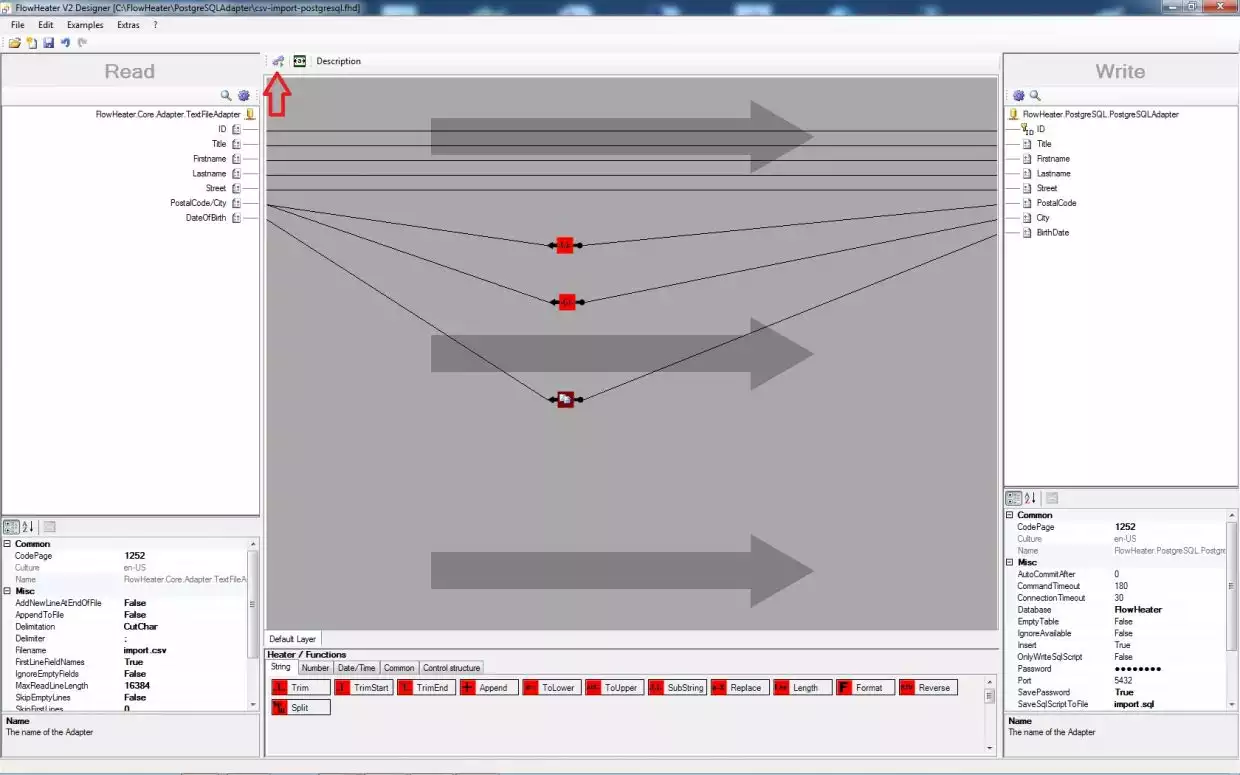 insert heater/functionsTwice drag and drop the SubString Heater from the string Heaters selection area at the bottom of the Designer page to roughly level with the fields of PostalCode and City on the design area. Connect the PostalCode/City field on the READ side to both these SubString Heaters. Then connect one of the Heaters to the PostalCode field and the second Heater to the City field on the WRITE side. Next double click on the SubString Heater you just connected to the PostalCode field. Enter in the popup that opens a Start Offset value of 1 and Length of 5 and confirm with OK. Repeat this for the Heater connected to the City field, but instead enter a Start Offset of 7 and a Length of 0. Your screen should now look like the screenshot on the right.
insert heater/functionsTwice drag and drop the SubString Heater from the string Heaters selection area at the bottom of the Designer page to roughly level with the fields of PostalCode and City on the design area. Connect the PostalCode/City field on the READ side to both these SubString Heaters. Then connect one of the Heaters to the PostalCode field and the second Heater to the City field on the WRITE side. Next double click on the SubString Heater you just connected to the PostalCode field. Enter in the popup that opens a Start Offset value of 1 and Length of 5 and confirm with OK. Repeat this for the Heater connected to the City field, but instead enter a Start Offset of 7 and a Length of 0. Your screen should now look like the screenshot on the right.
Note: The length of 0 we specified for City means until the end of the string.
Execute the definition
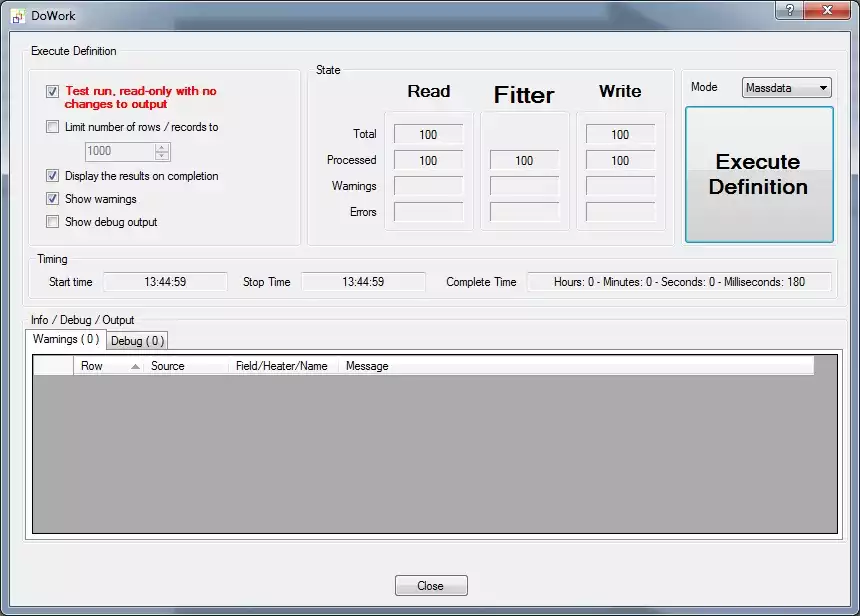 Execute the definitionNow execute the definition, either by clicking on the command button (circled in red) or by pressing F5 on the keyboard. This opens the FlowHeater execute and test window (see below). It is always prudent to first test an import before committing the actual changes to a database. So first try a test and check the results in this "Test and Execute" window. Leave the "Test run" option checked and click on the "Start Definition" button.
Execute the definitionNow execute the definition, either by clicking on the command button (circled in red) or by pressing F5 on the keyboard. This opens the FlowHeater execute and test window (see below). It is always prudent to first test an import before committing the actual changes to a database. So first try a test and check the results in this "Test and Execute" window. Leave the "Test run" option checked and click on the "Start Definition" button.
The label of the button will briefly change to read "Abort" and then the following window will appear. Note: The "Abort" button can be used to break off a time-consuming execution of a FlowHeater Definition at any point.
CSV import results
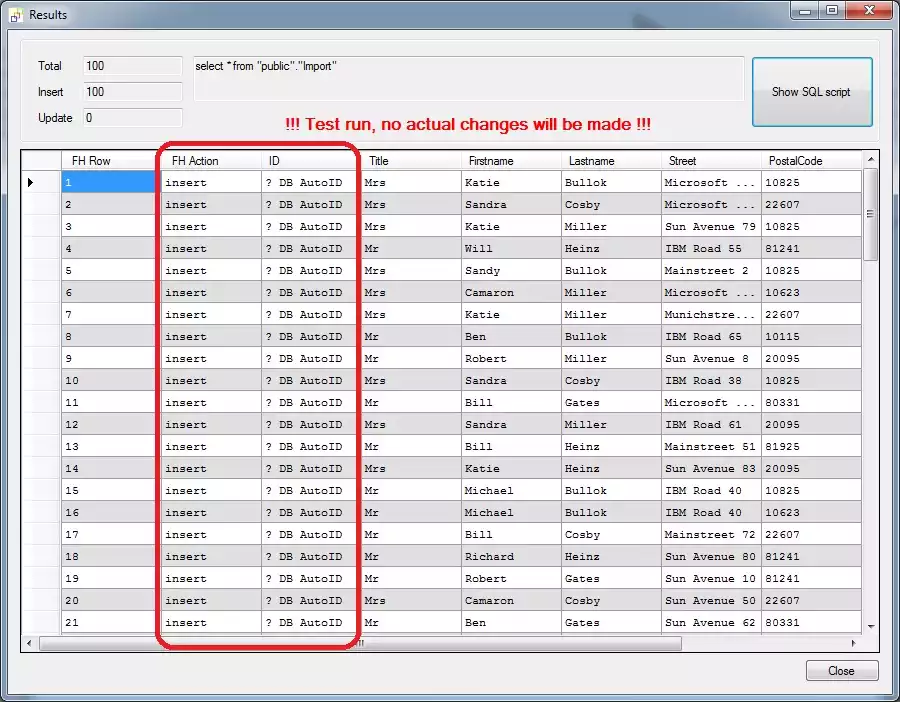 CSV import resultsHere we can see that FlowHeater has automatically recognized the ID field as an PostgreSQL SERIAL (AutoID) data type. Close the window, uncheck the "Test run" option in the Execute and Test popup window and click Start Definition again. Now our CSV text file is actually written to the Import table in your PostgreSQL database. Notice that the values in the ID column are now assigned actual values and in the first column "FH Action" has the value of insert. Run the Definition a second time and you will see that FlowHeater has recognized that this time it is a revision and so update appears in the "FH Action" column.
CSV import resultsHere we can see that FlowHeater has automatically recognized the ID field as an PostgreSQL SERIAL (AutoID) data type. Close the window, uncheck the "Test run" option in the Execute and Test popup window and click Start Definition again. Now our CSV text file is actually written to the Import table in your PostgreSQL database. Notice that the values in the ID column are now assigned actual values and in the first column "FH Action" has the value of insert. Run the Definition a second time and you will see that FlowHeater has recognized that this time it is a revision and so update appears in the "FH Action" column.
Open the Configurator of the PostgreSQL Adapter and uncheck the option Update data. Press the Start Definition button again and observe the result this time (with and without a test run). This time FlowHeater inserts the records into the database again. You may be wondering why it is that the ID field is not copied from the CSV data into the database, because a Pipe connects them? The reason is it depends on the ID field, which is automatically assigned by the PostgreSQL database because it has the SERIAL data type and the Pipe is only needed for updates.