The TextFile Adapter is used for the import, export and converting of TXT files to CSV and many other formats. The Adapter can be assigned to both READ and WRITE sides of a conversion. If you want to read or write CSV, TXT, ASC, ASCII, flat files or other text files and convert or transform these into any other format, the TextFile Adapter is perfect for the job. Please also refer to the general information about the usage of Adapters.
Of all the text file formats, CSV (Comma Separated Value) is probably the most popular. The FlowHeater’s TextFile Adapter comprehensively supports CSV files and practically any tabulation of data in text form as well as conversions of the most varied mixtures of character encodings (codepages). The default encoding is the codepage currently configured for your operating system, but alternative codepages can be specified and the actual selection is stored along with the Definition. For example, a Definition could have been created on a German workstation, but can later be executed without causing any problems using the batch module on a Windows Server, where the system codepage is configured for English. Support for DOS (ASCII), Unicode (utf7, utf8, utf16, utf32) as well as EBCDIC (IBM mainframe) is included. The encoding expected for input or chosen for output is simply selected in the "code page" dropdown. On the READ side when selecting a UTF/Unicode file with BOM (byte order mark) the correct code page will be recognized automatically.
Adapter settings in the General tab
Filename:  Choose a CSV text fileAn absolute or relative path to the file to be read or written. Relative paths are always relative to the folder the Definition file is saved in. Clicking on the “…” button at the end of the filename field opens the familiar operating system file selection window, where you can choose a file to open or navigate to the folder you wish to save the file in.
Choose a CSV text fileAn absolute or relative path to the file to be read or written. Relative paths are always relative to the folder the Definition file is saved in. Clicking on the “…” button at the end of the filename field opens the familiar operating system file selection window, where you can choose a file to open or navigate to the folder you wish to save the file in.
There is no support for wildcards such as *.csv here. If you want to process several text files in a folder you need to use the Batch Module with the option “/ReadFileName *.csv”.
On the READ side http:// or https:// for the resource location of a file can be used. The file must be openly available; presently no user login to a web server is supported.
The first row contains column headings: This checkbox allows you to select whether the first line starts with data or contains field names. If ticked on the READ side, the field names are automatically extracted from the text file and become the default field names for the Definition. On the WRITE side, this option confirms that the field names as specified in the Definition are to be written as the first output row.
Dynamically allocate columns by field names: This instructs the TextFile Adapter to allocate the correct fields dynamically according to the CSV column headings found in the text file.
Codepage: Selects the character encoding to assume or generate.
e.g.
850 = MS DOS ASCII Western European
1252 = Windows ANIS Western European
65001 = Unicode UTF-8
...
Note: READ and WRITE sides can be assigned different codepages.
Delimitation: With these radio buttons you select how the fields in your text file or flat file are divided from one another. The two options are With delimiters and Fixed width. If you opt to use delimiters, you select which one to use on the Delimiter tab (see below). If you switch back and forth between the two options, the default fixed width of 10 may become set. This can be reset to zero by using the Reset field widths button.
Line break: Here you can choose between “DOS / Windows ”, “UNIX / Linux” or alternatively “User defined terminator”. These terms mean:
- DOS / Windows: When reading or writing text files of this type, each line is terminated by a sequence of two bytes “CR LF (0x0D0A)”.
- UNIX / Linux: Lines are terminated by just a single byte “LF (0x0A)” in this format.
- User-defined terminator: This gives you the option to enter any desired character (or string of characters) to be used for line breaks in the text box alongside. The TextFile Adapter will treat these characters as line breaks on reading or writing.
The option "Terminate final record/row with a line break" instructs the TextFile Adapter to ensure that the last row written to the file is followed by a line break.
Blank lines in the text file are ignored if the "Skip empty lines" option is checked. The defined CSV separator, tab or other white space characters contained in the column data are also ignored. That means that a row consisting purely of CSV separator characters will also be filtered out.
 Choose a field delimiter
Choose a field delimiter
Adapter settings in the Delimiters tab
Delimiter: For a CSV file you specify here which delimiter separates the fields being read or should be output to separate the fields written. The standard delimiter is the semi-colon character. If none of the alternatives offered here apply, you can select the "other" option and enter a special character or string in the text box beside it.
Quotation marks: It is common in CSV files, but also in flat files with fixed column sizes, that fields containing text are surrounded by quote marks . The standard is without quotation marks.
123;"Text fields can contain anything; including a delimiter";€100.51;...
You can choose from a selection of characters that are popular for quotation marks here, or define your own special character. Note: If you also selected a fixed width, then the two quotation characters are included in the field’s maximum length. For example, in a field of maximum 20 characters, only 18 characters are left for data.
Only apply to STRING data types: This option tells FlowHeater to only use the specified quotation marks for fields of STRING data type.
Also use for column headings: If you select this option, the settings for field quotation marks also apply for column headings.
Ignore empty fields: If this option is selected, then the quotation marks will not be output for empty fields. This means that empty fields are simply indicated by two consecutive delimiters, making the output more compact.
Check if column delimiter occurs within quoted text: When this option is selected (default) determines whether or not a CSV column delimiter character may appear inside quotation marks.
Automatically replace doubled string delimiter characters embedded in field contents with one character: When the chosen string delimiter character can occur as a normal character in a CSV field content these are normally masked by the CSV string delimiter character simply being repeated. When this option is checked, the TextFile Adapter will collapse these duplicated characters while reading - in other words two consecutive CSV string delimiter characters will automatically become a single character.
When this option is used on the WRITE side, any string delimiter character encountered within the CSV field content will be automatically masked, meaning it is doubled/quoted - in other words a single CSV string delimiter character in the data will automatically become two.
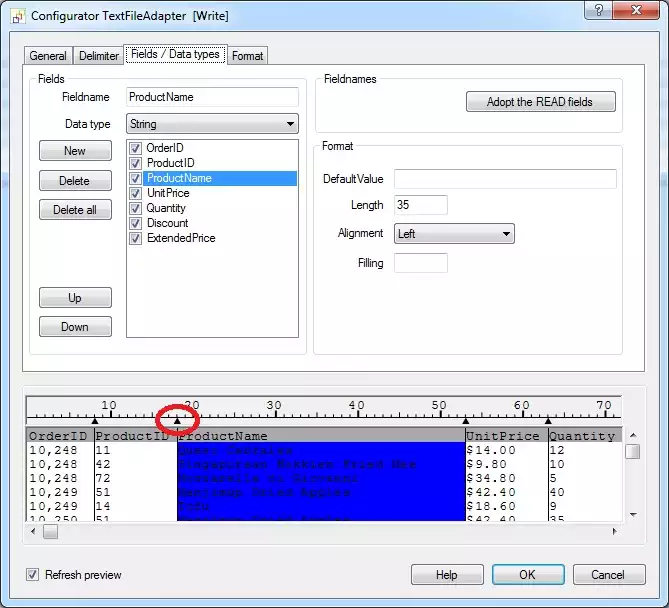
Adapter settings in the Field / Data Types tab
In this tab you can adjust the fields that are considered a part of the data; ignoring or removing fields and inserting new fields / columns and amend the assignment of fields types. The input again from READ Adapter button fetches the column names afresh from the text file. This option is only available on the READ side.
Simply click on a field name in the fields list to select the field to be moved or amended; this highlights the field in this list and its details appear in the Field name and Format sections.
The sequence of processing the currently selected field can be amended here quite easily, by using the Up and Down buttons.
In the Field name text box, the heading assigned to the currently selected field can be amended.
Format: In this section you can specify the field Length and Alignment (left or right justified ). Fixed field widths can either be adjusted explicitly in the Length box or graphically by using the left mouse button to drag the triangular tab stop markers along the ruler (circled here in red). The Pad character is used to define which character is used to fill out the remaining space in any fixed length field that is shorter than its maximum width (left or right justified). The standard character used is a space. Note that this only applies to fixed length fields.

Header / footer rows tab
Using this tab you control the processing of additionally available or to be output CSV header and footer row(s). The processing of header/footer rows does not operate along with the defined data columns, rather for entire rows. Each header/footer row is thereby represented by a separate Parameter.
On the READ side: The complete row(s) are available in predefined Parameters for further processing. Extracting these values during processing is achieved using the Get Parameter Heater.Note: The content of footer row(s) is also read prior to data processing and so is already available for processing by the time the first data row is read.
On the WRITE side: The value contained in the specified Parameter is written to the defined row. The contents of Parameters can be set or modified during the run using the Set Parameter Heater.
The option "Write header rows as a final step in processing" enables you to determine that the contents of the defined Parameters the header row(s) are only written to the CSV file after completion of processing. For example, this enables the results of calculations to be included in header row(s) that are accumulated from the data during processing and only written to the top of the CSV file as a final step.
Settings in the Advanced tab
 TextFile Adapter - Advanced CSV settingsAutomatically strip spaces from start and end of field data: If you select this option any leading or trailing space characters are automatically removed from each field/column.
TextFile Adapter - Advanced CSV settingsAutomatically strip spaces from start and end of field data: If you select this option any leading or trailing space characters are automatically removed from each field/column.
Allow line breaks in columns (reading only) With this option you can define whether line breaks are permitted in the field content. You can use this to read, for example, a CSV file that contains line breaks without it leading to column or field displacement. This option is only usable on the READ side.
Automatically replace line breaks with This option allows you to specify a substitute character that is used for the automatic replacement for line breaks. This is useful when data from an SQL database is exported, for example, that has embedded line breaks. All line breaks in the field contents are replaced.
Maximum length of each row This informs the TextFile Adapter the longest permitted line size.
Suppress writing empty header and footer rows With this option you control whether to suppress empty header or footer rows when otherwise selected for output.
Adapter settings in the Format tab
Examples
- HelloWord1, HelloWorld2 and HelloWorld3 - These examples explain how FlowHeater is generally operated.
- Converting a CSV file into a text file with fixed column widths
- Transforming a flat text file into an MS-DOS ASCII CSV text file
- Processing of CSV header and footer rows
- Importing a CSV file into an MS Access database table
- Importing a CSV file into an MS SQL Server database table
- Exporting an MS SQL Server database table as a flat text file (a printable format with fixed column widths)
- Extracting data from a partially unstructured flat text file and how values on many lines can be grouped and summed together