News
TextFile Adapter with support for header and footer rows
Release notes for version 2.4.1 on August 20, 2012
TextFile Adapter with support for header and footer rows
Based on FlowHeater parameters, header and footer rows on CSV text files can now also be processed with the TextFile Adapter.
Addition Heater with total accumulated for the whole run
This function enables the sum total of a complete run to be accumulated. An example of the possible uses of the feature includes calculating a total for the header and/or footer rows of CSV files or flat file reports.
Filter duplicated entries out
Release notes for version 2.4.0 on July 23, 2012
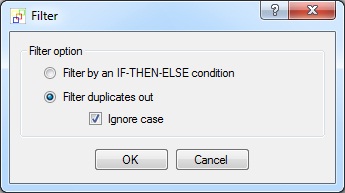
Filter duplicated entries out
The Filter Heater has been extended to provide a powerful new function. Repeated (duplicate) records or rows in the READ data source can now be filtered out with the Filter Heater. And in order to detect duplicate record/rows the data source does not need to be sorted!
Skipping empty lines
A further useful function has been added to the TextFile Adapter to ignore empty lines when reading (importing) text files (CSV, TXT, Flat File).
Improved handling of default values
Release notes for version 2.3.1 on May 26, 2012
Improved handling of default values
When the value of a field contains DBNULL, NULL or an empty string, the field’s default value defined in the FlowHeater Definition will now be used.
New numeric data type DOUBLE
Release notes for version 2.3.0 on May 7, 2012
New numeric data type DOUBLE
The existing FlowHeater numeric data types INTEGER, DECIMAL and CURRENCY were optimized for financial mathematics to avoid the occurrence of rounding differences. A new data type DOUBLE is now introduced for the higher precisions required in scientific calculations. The FlowHeater DOUBLE data type can process the SQL data types of float, real, single and double.
New export option for the TextFile Adapter
Release notes for version 2.2.6 on April 10, 2012
New export option for the TextFile Adapter
The TextFile Adapter has supported appending to existing text files on the WRITE side (export) for some time. Until now column field names were never added a second time to an existing text file. As of this version you can specify, in the case of appending to an existing file, whether column headings should be suppressed or not.