CSV Export auf mehrere Dateien aufteilen (splitten)
In diesem Beispiel erklären wir wie mit dem FlowHeater „große“ SQL Server Tabellen exportiert und auf mehrere CSV Textdateien aufgeteilt/segmentiert werden können. Die Aufteilung der CSV Dateien kann dabei über einen Feldinhalt oder aber anhand eines statischen Wertes, der angibt wie viele Datensätze max. in eine CSV Datei exportiert werden sollen, erfolgen.
Vorbereitung / Hintergrundwissen
Der Export der Daten geht immer über den Textfile Adapter auf der WRITE Seite zum Schreiben der CSV Dateien. Das Problem dabei ist, es müssen irgendwie dynamisch unterschiedliche CSV Dateinamen generiert werden. Das Zauberwort hier heißt Parameter. FlowHeater Parameter können einmal über den SET Parameter Heater während des CSV Exportes gesetzt bzw. verändert werden, sowie können diese Parameter auch als dynamische CSV Dateiname im TextFile Adapter verwendet werden. Der Clou dabei ist, dass der Textfile Adapter pro Datensatz prüft ob sich der Dateiname geändert hat und erstellt bzw. öffnet dynamisch eine neue/andere Datei.
Segmentierung (Splitten) anhand eines Feldinhaltes
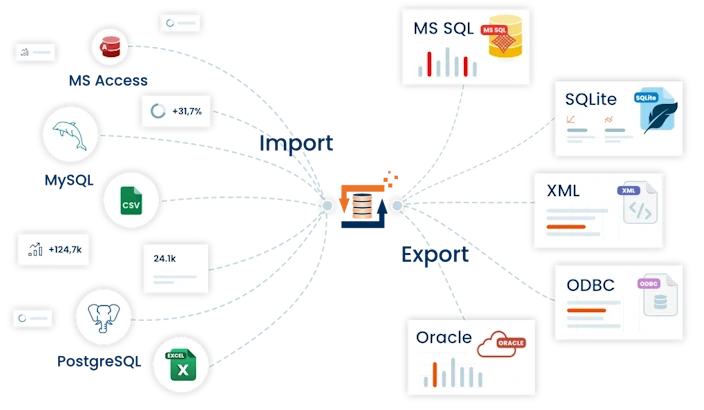
 CSV Export empfohlene EinstellungenDas ist der einfache Fall. Hierfür müssen wir nur einen Parameter z.B. SEGMENT anlegen. Diesen Parameter weisen wir über den SET Parameter Heater den Feldinhalt der SQL Server Tabelle zu, das die benötigte Segmentierung (z.B. eine Artikelkategorie, Adressentyp, etc.) enthält. Jetzt müssen wir nur noch diesen Parameter als Dateiname oder aber als Teil eines Dateinamen im Textfile Adapter setzen.
CSV Export empfohlene EinstellungenDas ist der einfache Fall. Hierfür müssen wir nur einen Parameter z.B. SEGMENT anlegen. Diesen Parameter weisen wir über den SET Parameter Heater den Feldinhalt der SQL Server Tabelle zu, das die benötigte Segmentierung (z.B. eine Artikelkategorie, Adressentyp, etc.) enthält. Jetzt müssen wir nur noch diesen Parameter als Dateiname oder aber als Teil eines Dateinamen im Textfile Adapter setzen.
Wichtig ist hier den Parameternamen mit dem Dollar „$“ Zeichen zu umschließen, siehe Beispiel oben.
Der Textfile Adapter ersetzt den aktuellen Inhalt des Parameters SEGMENT und geniert daraus einen vollständigen Dateinamen. Die weiteren Einstellungen im Textfile Adapter hängen nun von Ihrer SQL Server Datenquelle ab. Am performantesten ist es die SQL Server Tabelle beim Abrufen gleich anhand der gewünschten Segmentierung sortiert auszulesen. Hierzu genügt es an den SQL am Ende ein ORDER BY [Segment Feldname] anzugeben. Das hat den Vorteil, dass der Textfile Adapter nicht bei jedem Datensatz eine neue Datei öffnen muss um evtl. nur einen weitere Datensatz in diese Datei zu exportieren. Mit dem ORDER BY ist gewährleistet, dass die Datensätze anhand der Segmentierung sortiert gelesen werden und der Texfile Adapter muss nur einmalig pro Segment einen neue Datei öffnen und kann diese solange geöffnet halten bis das nächste unterschiedliche Segment gelesen wird. Wenn das machbar ist genügt es zusätzlich noch anzugeben ob evtl. CSV Spaltenüberschriften ausgegeben werden sollen oder nicht.
Kann die Datenquelle nicht sortiert ausgegeben werden, ist es erforderlich im TextFile Adapter die Option „An vorhandene Datei Anfügen“ zu aktivieren. Evtl. vorhandene CSV Datei müssen so vor jedem Start des Exportes manuell gelöscht werden.
Export max. (n) Datensätze pro CSV Datei
Hinweis: Ab Version 4.1.1 unterstützt der AutoID Heater diese Option. Es ist damit nicht mehr wie unten beschrieben der Umweg über den .NET Script Heater notwendig. Einfach den .NET Script Heater in den AutoID Heater tauschen, fertig.
 CSV Export über SkriptHier ist etwas Programmierung mittels des .NET Script Heater erforderlich. Das klingt für nicht Programmierer wahrscheinlich komplex, ich kann Sie aber beruhigen, das Skript kann sehr leicht an eigene Bedürfnisse angepasst werden.
CSV Export über SkriptHier ist etwas Programmierung mittels des .NET Script Heater erforderlich. Das klingt für nicht Programmierer wahrscheinlich komplex, ich kann Sie aber beruhigen, das Skript kann sehr leicht an eigene Bedürfnisse angepasst werden.
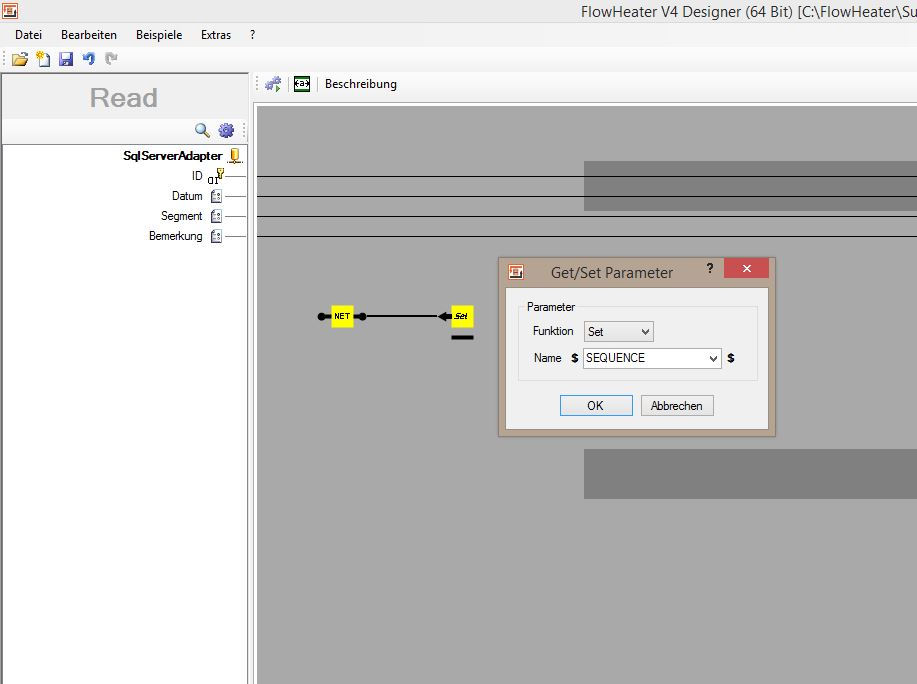
Das Vorgehen ist im Prinzip das Gleiche wie oben, wir benötigen einen Parameter der in diesem Fall eine fortlaufende Nummer für die gerade aktuell zu exportierende CSV Textdatei enthält. Diese fortlaufende Nummer wird dabei mittels des Skriptes berechnet, zurückgegeben und anschließend über den SET Parameter Heater der Parameter „SEQUENCE“ gesetzt. Diesen Parameter verwenden wir wiederum im TextFile Adapter als Platzhalter für den Dateinamen.
Einstellungen für .NET Script Heater
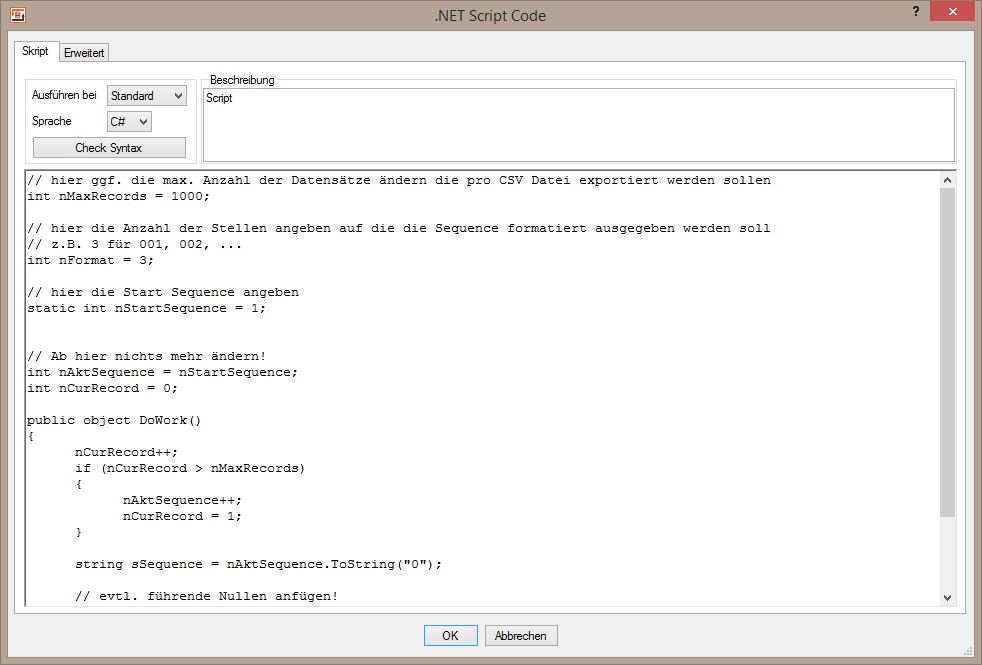 .NET Skript EinstellungenDas unten stehende Skript (C# bzw. VB.NET) muss lediglich in den .NET Script Heater kopiert werden. An den kommentierten Stellen können einige Einstellungen z.B. wie viele Datensätze pro CSV Datei max. exportiert werden sollen, etc. vorgenommen werden. Anschließend muss der Ausgang mit dem SET Parameter Heater verbunden werden um den Parameter „SEQUENCE“ zu setzen.
.NET Skript EinstellungenDas unten stehende Skript (C# bzw. VB.NET) muss lediglich in den .NET Script Heater kopiert werden. An den kommentierten Stellen können einige Einstellungen z.B. wie viele Datensätze pro CSV Datei max. exportiert werden sollen, etc. vorgenommen werden. Anschließend muss der Ausgang mit dem SET Parameter Heater verbunden werden um den Parameter „SEQUENCE“ zu setzen.
Hinweis: Bei der Verwendung von VB.NET muss die Sprache noch manuell in den Einstellungen von „C#“ auf „VB“ umgestellt werden.
C# Skript
// hier ggf. die max. Anzahl der Datensätze ändern die pro CSV Datei exportiert werden sollen
int nMaxRecords = 1000;
// hier die Anzahl der Stellen angeben auf die die Sequence formatiert ausgegeben werden soll
// z.B. 3 für 001, 002, ...
int nFormat = 3;
// hier die Start Sequence angeben
static int nStartSequence = 1;
// Ab hier nichts mehr ändern!
int nAktSequence = nStartSequence;
int nCurRecord = 0;
public object DoWork()
{
nCurRecord++;
if (nCurRecord > nMaxRecords)
{
nAktSequence++;
nCurRecord = 1;
}
string sSequence = nAktSequence.ToString("0");
// evtl. führende Nullen anfügen!
while( sSequence.Length < nFormat)
sSequence = "0" + sSequence;
return sSequence;
}
VB.NET Skript
' hier ggf. die max. Anzahl der Datensätze ändern die pro CSV Datei exportiert werden sollen
Dim nMaxRecords as Integer = 1000
' hier die Anzahl der Stellen angeben auf die die Sequence formatiert ausgegeben werden soll
' z.B. 3 für 001, 002, ...
Dim nFormat as Integer = 3
' hier die Start Sequence angeben
Dim nStartSequence as Integer = 1
' Ab hier nichts mehr ändern!
Dim nAktSequence as Integer = nStartSequence
Dim nCurRecord as Integer = 0
Public Function DoWork() As Object
nCurRecord = nCurRecord + 1
if nCurRecord > nMaxRecords
nAktSequence = nAktSequence + 1
nCurRecord = 1
End If
Dim sSequence as String = nAktSequence.ToString("0")
' evtl. führende Nullen anfügen!
While sSequence.Length < nFormat
sSequence = "0" + sSequence
End While
return sSequence
End Function
Hinweis
Das hier beschriebene Vorgehen, zum Aufteilen eines Datenexportes in mehrere kleinere CSV Dateien, funktioniert nur im „Massendaten“ Modus. Das Problem am „Memory“ Modus ist, dass pro Step
alle Datensätze verarbeitet werden ohne das der nachfolgende Step davon was mitbekommt. Das bedeutet, dass gesetzte Parameter im letzten Step der Verarbeitung, beim eigentlichen Schrieben der CSV Daten, immer den letzten Wert widerspiegeln und alle Datensätze in dieser Datei landen würden.
Beispiele
Über folgenden Forumsbeitrag können drei kleine Beispiele heruntergeladen werden die das Ganze etwas besser verdeutlichen: Daten SQL-Server auf mehrere CSV-Files aufteilen