CSV export divided into several files
In this example we explain how to export with FlowHeater cumbersomely large SQL Server tables and split (segment) them into a series of CSV text files. The criterion for dividing the CSV files can be based on the content of a field or a fixed value for the maximum number of records to export.
Preparation / background information
For exporting the data, the TextFile Adapter is always used on the WRITE side to write the CSV files. The problem here is to somehow generate dynamically assigned unique CSV file names. Parameters are key to achieving this. Parameters in FlowHeater can be defined and modified using the SET Parameter Heater during the CSV export, and the selfsame Parameter settings can be used to compose a dynamic CSV file name in the TextFile Adapter. The trick here is that the Textfile Adapter checks prior to writing each record whether the file name has been amended and if so creates a new file or opens an alternative file for output dynamically.
Segmenting on field content
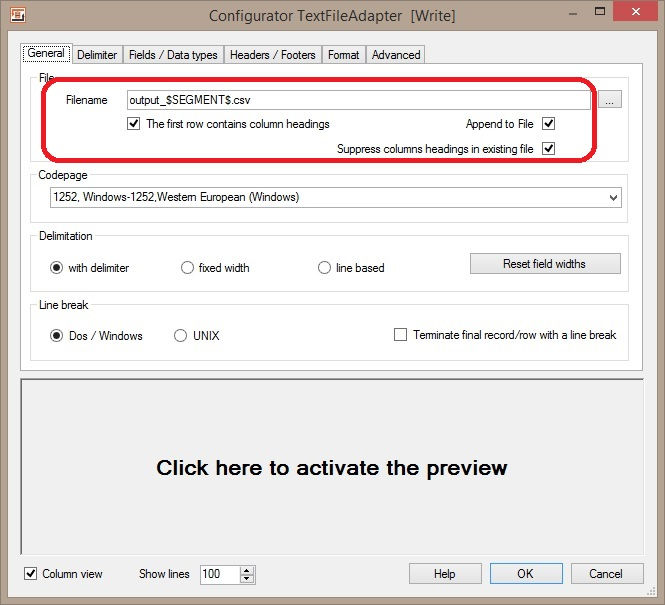 Standard csv export settingsThis is the simplest case. To achieve this we have to define a Parameter e.g. SEGMENT. We assigne this Parameter using the SET Parameter Heater from the field in the SQL Server table that contains the required segmentation factor (e.g. a product category, address type, etc.). All that remains necessary is to use this Parameter to define the file name or a part of the file name in the Textfile Adapter.
Standard csv export settingsThis is the simplest case. To achieve this we have to define a Parameter e.g. SEGMENT. We assigne this Parameter using the SET Parameter Heater from the field in the SQL Server table that contains the required segmentation factor (e.g. a product category, address type, etc.). All that remains necessary is to use this Parameter to define the file name or a part of the file name in the Textfile Adapter.
It is important to remember to surround the Parameter name with “$” (dollar signs), as in the example above.
The Textfile Adapter substitutes the current content of the SEGMENT Parameter and generates a complete file name. Further settings in the Textfile Adapter depend on the data in your SQL Server table. For the best performance you should ensure the SQL Server select delivers a sorted sequence by the desired segmentation. For this it suffices to add an ORDER BY [segment field name] to the SQL select. The advantage of this is that the Textfile Adapter does not need to open a new file as frequently, possibly for each record it exports. The ORDER BY clause ensures that the records are sorted according to the segmentation and so the Adapter can keep the file open as long as possible and only open a new file name when the actual segment changes. If applicable, all that remains is to indicate whether or not CSV column headings should be output.
When the source data cannot be sorted, it is necessary to check the TextFile Adapter option “Append data to existing file”. Potentially existing CSV files must therefore be deleted manually before starting the export.
Export a maximum (n) records per CSV file
Note: The AutoID Heater has supported this option since FlowHeater version 4.1.1. The workaround of using a .NET Script Heater as described below is no longer necessary. Simply swap out the .NET Script Heater for the AutoID Heater.
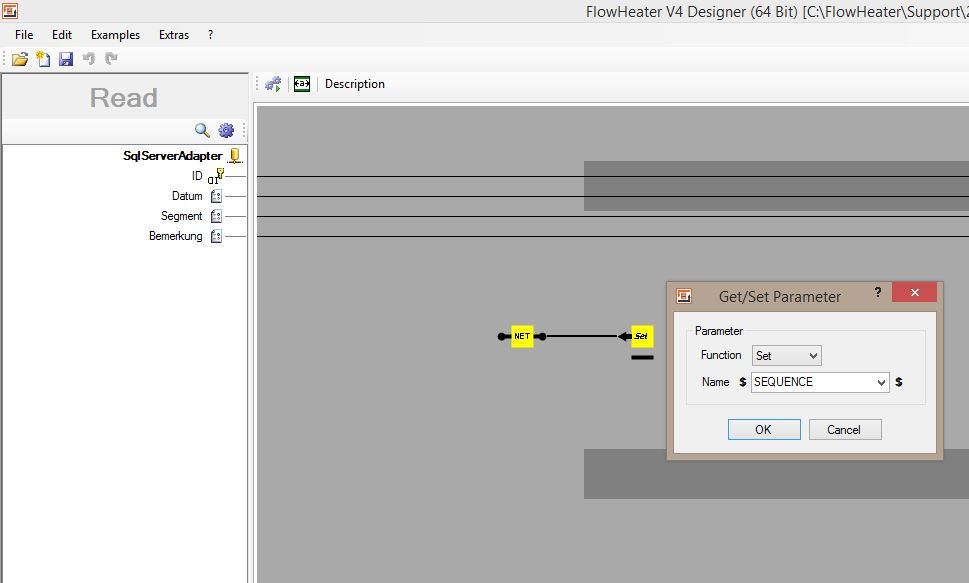 CSV export using scriptTo achieve this demands a little programming and use of the .NET Script Heater. That may sound rather complicated for non-programmers, but I can assure you it is really easy to adapt this example script to your actual needs.
CSV export using scriptTo achieve this demands a little programming and use of the .NET Script Heater. That may sound rather complicated for non-programmers, but I can assure you it is really easy to adapt this example script to your actual needs.
In principle the method is similar to the above, but in this case we require a Parameter that contains a consecutive number to label the actual exported segments of the CSV text file. This consecutive number is calculated by a script and returned as a value that is delivered to the SET Parameter Heater, which in turn amends a Parameter (e.g. “SEQUENCE”). Again, we use this Parameter in the TextFile Adapter as placeholder for the file name.
Settings for the .NET Script Heater
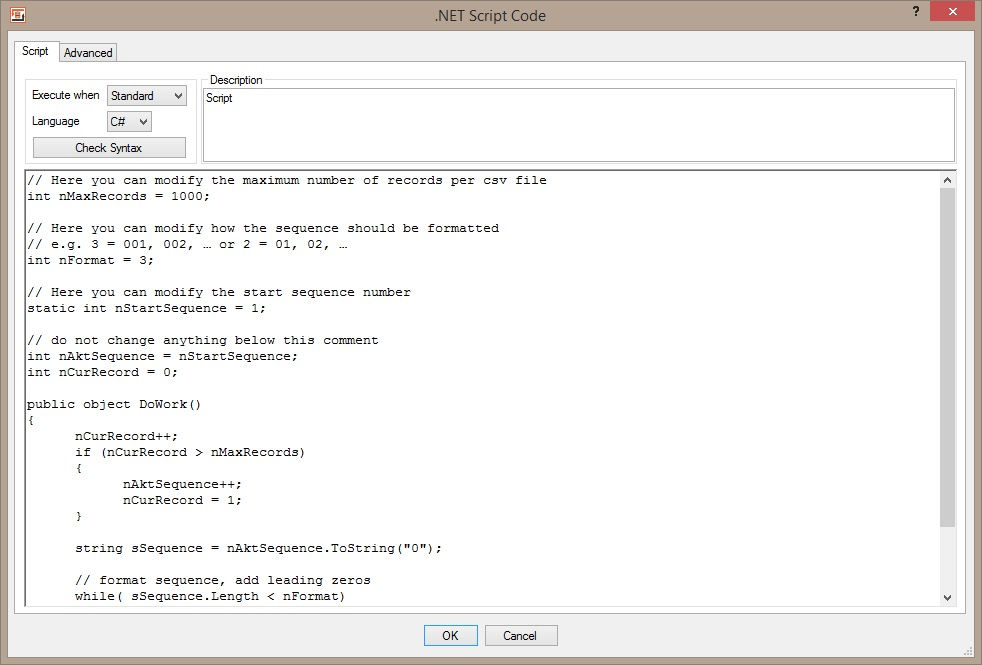 .NET Script settingsThe script below (C# or VB.NET) must simply be copied into the .NET Script Heater. Commented points in the script may be amended as desired, e.g. to determine how many records as a maximum are output as a separate CSV file, etc. The output of the .NET Script Heater must then be connected to the input of the SET Parameter Heater to assign the Parameter “SEQUENCE”.
.NET Script settingsThe script below (C# or VB.NET) must simply be copied into the .NET Script Heater. Commented points in the script may be amended as desired, e.g. to determine how many records as a maximum are output as a separate CSV file, etc. The output of the .NET Script Heater must then be connected to the input of the SET Parameter Heater to assign the Parameter “SEQUENCE”.
Note: When using VB.NET the language in the settings must be amended manually from “C#” to “VB”.
C# Script
// Here you can modify the maximum number of records per csv file
int nMaxRecords = 1000;
// Here you can modify how the sequence should be formatted
// e.g. 3 = 001, 002, ... or 2 = 01, 02, ...
int nFormat = 3;
// Here you can modify the start sequence number
static int nStartSequence = 1;
// do not change anything below this comment
int nAktSequence = nStartSequence;
int nCurRecord = 0;
public object DoWork()
{
nCurRecord++;
if (nCurRecord > nMaxRecords)
{
nAktSequence++;
nCurRecord = 1;
}
string sSequence = nAktSequence.ToString("0");
// format sequence, add leading zeros
while( sSequence.Length < nFormat)
sSequence = "0" + sSequence;
return sSequence;
}
VB.NET Script
' Here you can modify the maximum number of records per csv file
Dim nMaxRecords as Integer = 1000
' Here you can modify how the sequence should be formatted
' e.g. 3 = 001, 002, ... or 2 = 01, 02, ...
Dim nFormat as Integer = 3
' Here you can modify the start sequence number
Dim nStartSequence as Integer = 1
' do not change anything below this comment!
Dim nAktSequence as Integer = nStartSequence
Dim nCurRecord as Integer = 0
Public Function DoWork() As Object
nCurRecord = nCurRecord + 1
if nCurRecord > nMaxRecords
nAktSequence = nAktSequence + 1
nCurRecord = 1
End If
Dim sSequence as String = nAktSequence.ToString("0")
' format sequence, add leading zeros
While sSequence.Length < nFormat
sSequence = "0" + sSequence
End While
return sSequence
End Function
Warning
The method described above for splitting an export into several smaller CSV file only works successfully with the “Mass data” mode. The problem here is that with “Memory” mode, for each step:
all the records are processed completely before anything is passed on to the next step. This results in assignment of the Parameter being deferred until the last step in the process, which will only reflect the final value, thus all records would land up in a single file named using the last value.