The InMemory Adapter was specially developed to take advantage of the constantly expanding amount of main memory that is free in computers/servers nowadays. For processing and preparation of large/complex FlowHeater Definitions, a considerable increase in performance is now possible.
In so doing the InMemory Adapter supports “any number” of “temporary” tables that can be used in a similar manner to SQL database tables. Unlike SQL database tables, InMemory tables, as their name suggests, are only held in main memory. The major performance advantage of InMemory tables arises from their fast access times, as there is no latency involved in establishing a connection, or network, etc. The volume of data that can be processed with the InMemory Adapter purely depends on the amount of the computer’s main memory that is free.
Possible data volumes of 32-bit (x86) versus 64-bit (x64)
No matter how much main memory is free, the FlowHeater 32-bit variant is constrained to using a maximum of 2 GB. However, the FlowHeater 64-bit variant can in principle address all the unused main memory available and make use of this for processing.
Sample calculation
Assuming the size of an individual record is 2 KB (2,048 bytes), which is in fact quite large. If there were a million (1,000,000) records then 2 GB would be needed for the user data.
2 KB x 1,000,000 = 2 GB
The InMemory Adapter requires approximately a further 20% for internal administration. This means that for processing a million records around 2.4 GB of free main memory is required in total. If more main memory than this is available then even larger volumes of data can be processed.
Important: Make sure there is always enough free main memory available to the system to ensure it is not forced to dump memory to a page file on disk! That would effectively slow down system processing and cancel out any performance gain.
Possible applications
With the InMemory Adapter it is possible to merge several data sources and to enrich existing data by adding information. Furthermore, large replacement lists for fast “CSV/Data Lookups” can be recorded temporarily. Access to these tables can be performed very effectively with the String Replace Heater (CSV Lookup), SQL Heater or Lookup Heater. These Heaters/Functions offer direct access to InMemory Adapter tables, resulting in a further significant gain in processing speed.
Configuration
General tab
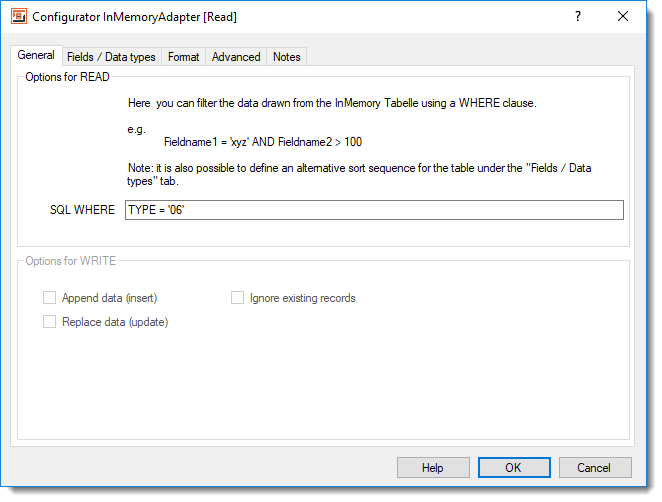 InMemory Adapter - General TabDepending which side of the InMemory Adapter is applicable, you are able to define the following settings.
InMemory Adapter - General TabDepending which side of the InMemory Adapter is applicable, you are able to define the following settings.
READ side: You do not have to read in the whole content of the temporary table every time, you can specify an SQL WHERE clause to filter the data obtained. The WHERE clause has the same syntax as a regular SQL database table.
WRITE side: Here you define what actions should be taken when writing to the InMemory Adapter table. The following options are available.
Append data (insert): When this option is checked the data is added with an “insert” into the temporary InMemory table.
Replace data (update): When this option is checked the InMemory Adapter attempts to replace existing records in the table with an update, matching the predefined key fields (or primary key).
Ignore existing records: When this option is checked it will prevent a duplication of existing records when inserting. To enable this to work, it is necessary that key fields are defined.
Note: The options “Append data (insert)” and “Replace data (update)” as well as “Append data (insert)” and “Ignore existing records” can be used in combination. The InMemory Adapter decides what action is needed based on the key field(s) defined under the “Fields / Data types” tab. For example , when insert and update options are both checked, if the key field(s) match it updates, otherwise it inserts. When only the update option is checked, not insert, only matching records are updated and others ignored.
Fields / Data types tab
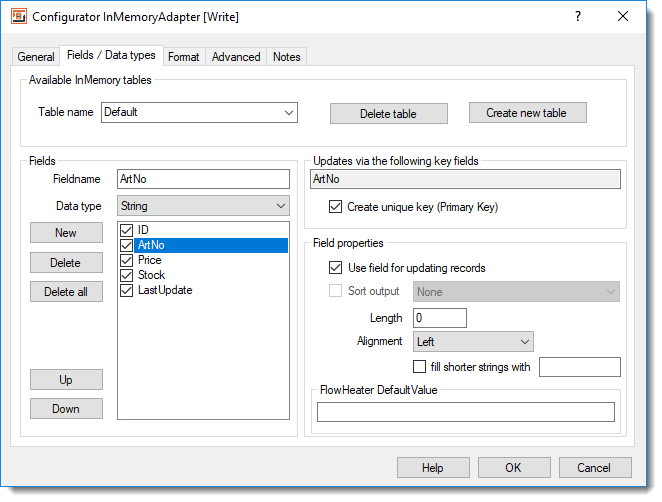 InMemory Adapter - Fields / Data types tabTemporary InMemory tables can be created, renamed, deleted and selected under this tab. A single table named “Default” is the original setting, but as many additional tables as required can be created. The tables can also contain as many fields as desired. If you change a field specification here (name, data type, etc.) then this field is automatically changed for all InMemory Adapters that reference the same InMemory table .
InMemory Adapter - Fields / Data types tabTemporary InMemory tables can be created, renamed, deleted and selected under this tab. A single table named “Default” is the original setting, but as many additional tables as required can be created. The tables can also contain as many fields as desired. If you change a field specification here (name, data type, etc.) then this field is automatically changed for all InMemory Adapters that reference the same InMemory table .
According to which side the Adapter is used, the following settings may additionally be used.
On the READ side: An optional sort sequence for the data extracted from the table may be specified here. It is possible to specify sorting over several fields. To sort the output, click on the desired field and check the option “Order by”. Next to this you can also specify whether sorting should be “Ascending” or “Descending”. When several sort fields are specified, the hierarchy of sorting can also be determined by the order that the fields are specified.
On the WRITE side: If the records in the table will be updated, then one or more key fields should be specified in the InMemory Adapter, by which the InMemory Adapter will attempt to identify existing records. Tip: In a series of processing steps several InMemory Adapter can be used that reference the same temporary table. However, the key field(s) are specified individually in each Adapter. This means it is possible to define different key field(s) for updating records in the different processing steps.
If in addition the option “Create unique (primary) key” is checked, the key is defined as having a distinct value. This option enables fast processing, especially when there is a lot of records, for locating and updating records using these key field(s). Warning: The data contained in these key field(s) must really be unique in the table as no records with the same key are permitted.
Adapter settings in the Format tab
Advanced tab
Extended settings
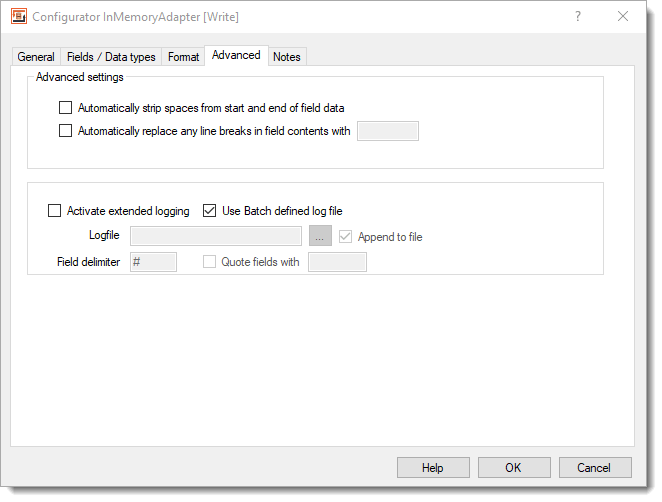 InMemory Adapter - Advanced TabAutomatically trim leading/trailing spaces in the content: When you check this option any space characters at the beginning and at the end of the field content are automatically removed. This setting only applies to fields with FlowHeater Datatype STRING.
InMemory Adapter - Advanced TabAutomatically trim leading/trailing spaces in the content: When you check this option any space characters at the beginning and at the end of the field content are automatically removed. This setting only applies to fields with FlowHeater Datatype STRING.
Automatically replace line breaks in field contents with: When you check this option any line breaks in the field content are replaced by the character in the box alongside.
Logging
Activate extended logging: This permits you to specify whether the Adapter should note what actions are performed in a specified logfile. When you check the “Append” option it will add to the end of any existing records, otherwise the logfile will be emptied prior to recording the log.
Use Batch defined log file: When you check this option the Adapter will use the logfile defined for the batch run for recording.
Field delimiter: This permits you to define the separator character that is used to divide individual field content in the log.
Quote fields with: Field content is surrounded by this character.