
Ladezeit der Seite: 0.208 Sekunden
FlowHeater - Der Daten Spezialist
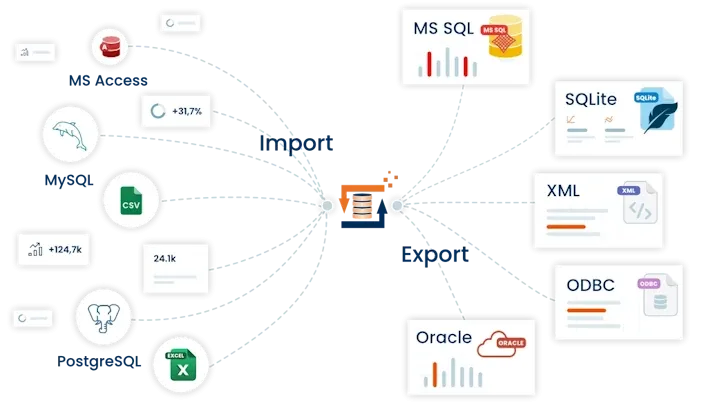
Effiziente Datenintegration und Transformation mit FlowHeater - Ihre Lösung für nahtlosen Datentransfer.
Effiziente Datenintegration und Transformation mit FlowHeater - Ihre Lösung für nahtlosen Datentransfer.