The ODBC data source Adapter is used to import (insert), export (select) and amend (update) tables from any chosen ODBC source. As well being attached to the READ (export) side, the Adapter can also be used on the WRITE (import) side. The only prerequisite is an installed ODBC driver for your data source.
Caution: 32-bit or 64-bit variant? To comply with the type of ODBC driver (32-bit / 64-bit) installed on your system you must use the corresponding FlowHeater variant to connect to an ODBC data source. The 64-bit FlowHeater variant cannot be used with 32-bit ODBC drivers and vice versa. If you encounter an error message stating that ODBC is non-installed or not available, simply try again using the alternative variant of FlowHeater (32-bit / 64-bit). Both FlowHeater variants can be installed in parallel on a computer.
General tab
Connection and authentication
 ODBC Adapter - database propertiesODBC source: There are two possible ways to identify the ODBC source here.
ODBC Adapter - database propertiesODBC source: There are two possible ways to identify the ODBC source here.
-
Using a configured ODBC source entry. ODBC sources are administered using the Windows option:
Start->Control Panel->Administrative Tools->ODBC - Using a complete ODBC connection string
Driver={Microsoft Access Driver (*.mdb)};DBQ=C:\Examples\Northwind.mdb
The links below provide detailed examples of connection strings for a variety of data sources:
https://www.connectionstrings.com/
User / Password If you enter values here, these are used to assemble the ODBC connection string. Let us suppose we have entered for ODBC data source [FlowHeater], for User [Me] and Password [Secret], the ODBC connection string would be assembled with:
DSN=FlowHeater; UID=Me; PWD=Secret
Important: The password entered is only permanently stored if you check the "Save Password" option. Should a password be saved, it is stored in an encrypted form in the Definition data.
Common
Insert data: When this option is checked, SQL Insert statements are generated.
Ignore existing records: During an import and when this option is checked, records that already exist in the table are ignored.
Empty the table before importing: When this is checked you tell the ODBC Adapter to empty the contents of the table prior to running the import, effectively deleting all existing rows.
Update data: When this option is checked, SQL Update statements are generated. Note: If both the Insert and Update options are checked, the ODBC Adapter checks whether an SQL Update or Insert should be generated in each instance, by reference to the PrimaryKey. Tip: If you are certain there is only data to insert then avoid checking the Update option, as this will make the process significantly faster.
Remove records (Delete): This will attempt to delete existing records by reference to the fields of the index “Primary Key”. Note: This option cannot be used together with the INSERT or UPDATE options.
No updates or inserts to data, only generate an SQL script: When this option is checked, it signals the ODBC Adapter to make no inline changes to the database, but instead to store an SQL script with Insert and/or Update statements. This is useful for testing during development and for subsequent application to the database. If this option is checked you should also check the option below and enter the filename that the SQL statements are to be stored in.
Generate SQL script: This option instructs the ODBC Adapter to store the change statements (Insert, Update) as an SQL script file with the specified name and path.
Fields / Data types tab
 ODBC Adapter - Fields / Data typesSQL: data available varies according to the side of the Adapter in use:
ODBC Adapter - Fields / Data typesSQL: data available varies according to the side of the Adapter in use:
On the READ side: here you can choose from Tables and Views.
On the WRITE side: only Tables are available.
On the READ side you also have the possibility to enter complex SQL statements in the text field. Table joins must be defined by hand. In the second combo box the tables and views are listed that are available in the specified ODBC database.
Fields: When you click the Load Schema button, information is retrieved from the database schema (field names, field sizes, data types, primary key, etc.) for the SQL statement above. The information about the fields is then loaded into the field list to the left of this button.
Note: The fields in the field list can be ordered in any sequence required. Fields that are not required can either be temporarily disabled here (tick removed) or simply deleted.
Field properties: How the properties of Primary Key and Auto Increment for the currently highlighted field are to be interpreted are adjusted. This information is only required on the WRITE side. No changes are needed here generally, since the correct information is usually obtained directly from the schema.
A PrimaryKey field is used in an Update to identify record that possibly exists.
Auto Increment fields are neither assigned nor amended in Insert/Update statements.
Warning: If you make changes here it can result in more than one record being updated with an Update!
Advanced tab
General
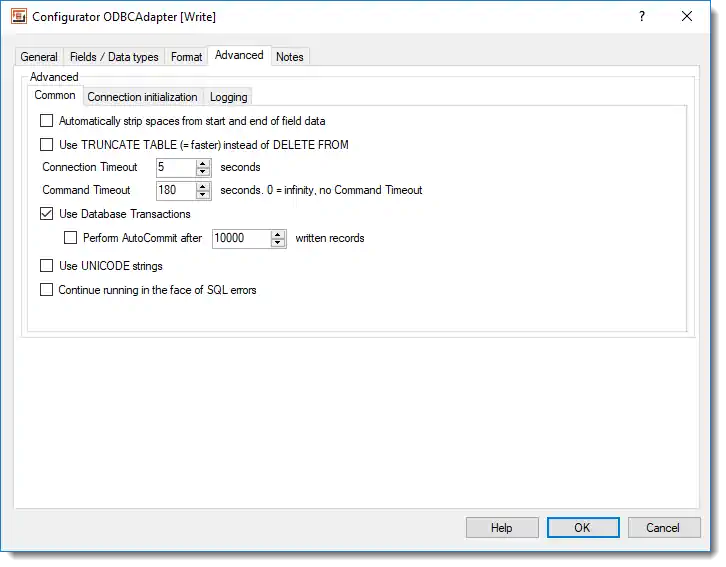 ODBC Adapter - extented propertiesAutomatically strip spaces from the start and end of content: If you check this option an auto trim of whitespace characters will be carried out on STRING data types. This means that any spaces, tabs and line break characters are automatically removed from the leading and trailing parts of strings.
ODBC Adapter - extented propertiesAutomatically strip spaces from the start and end of content: If you check this option an auto trim of whitespace characters will be carried out on STRING data types. This means that any spaces, tabs and line break characters are automatically removed from the leading and trailing parts of strings.
Use TRUNCATE TABLE (=quicker) instead of DELETE FROM: When the option “Empty the table before importing” under the General tab is checked “TRUNCATE TABLE” instead of “DELETE FROM” (=default) is used to empty the table content.
Connection timeout: Timeout in seconds while waiting for connection to be established. If no connection has been made after this period, then the import/export run is aborted.
Command timeout: Timeout in seconds while waiting for an SQL command to complete. By entering a zero value here, effectively disables the option altogether. In that case SQL commands will never timeout and are awaited endlessly. This option makes sense when you select massive data volumes from a database on the READ side and the ODBC datasource takes a long time to prepare its result.
Use database transactions: This allows you to control how data is imported. According to the default settings ODBC Adapter uses a single “large” transaction to secure the entire import process. When importing extremely large volumes you may have to adapt transactional behavior to your needs using the “Run AutoCommit after writing every X records”.
Use UNICODE strings: When checked this option will force output of a prefix to the initial apostrophe. e.g. N’import value’ instead of ‘import value’.
Continue running in the face of SQL errors: This option allows you to instruct FlowHeater not to abort a run when it encounters an ODBC database error. Warning: This option should only be used in exceptional circumstances, because database inconsistencies could result.
Connection initialization
User-defined SQL instructions for initializing the connection: You can place any user-defined SQL commands here, which will be used for initializing the connection after a connection to the ODBC data source has been established.
Adapter settings in the Format tab